亚搏yabo(中国) 中外医疗AI评估圭臬有色差? 中国机构发布榜单 WiseDiag、Gemini、OpenAI GPT位列三甲
文/新浪财经香港站赵岚
“先问AI后问医”,当市集老师依然完成,越来越多东说念主在有微恙小痛时更倾向于问AI得回即时性谜底,而非破费大齐的时分去病院列队就诊。但医疗行为专科性极强的鸿沟,AI问诊确实可靠吗?咱们应该以什么圭臬来评估AI的准确性与专科度?
AI问诊的常用场景:健康惩处慢病惩处
市集上医疗类AI大模子过头丰富,当中包括头部大厂的通用大言语模子、健康惩处APP、依附于应酬软件的小要领等,均可提供问诊类医疗见解。但不同平台给出的谜底存在互异,可能导致问诊者困惑,以致被失实辅导。
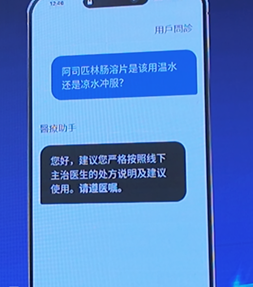
“AI的回答无意首尾乖互,当我第一次问诊时他会给我推选几种药,但我第二次补充症状后,他会给我推选其他几种药,几款药品之间的作用是相通的,以致中、西药之间照旧相斥的。”有效户暗示对AI不信任,由于AI所带的特质会“投合”用户,即使无法准确判断病情,也会基于有限信息给出笼统或失实的提议。
还有些AI为幸免包袱风险,复兴更像是“精确的鬼话”,比如机械回复“遵医嘱”。用户本想得回参考提议,这么的应对十足没特敬爱。
“当今AI不是小众的科技,‘AI+医疗’TOC鸿沟最刚需的场景是健康惩处和慢病惩处”,德适生物科技(2526.HK)居品肃肃东说念主何迅对新浪财经暗示。
由于AI并不具备如大夫般的临床教养,无法针对个体症状与患者进行深度对话,因此用户在问诊时自行提供的信息时常不够全面、败落要津检测数据,导致AI漏诊概率高。
何迅暗示,现时市集端智能体天然供给迷漫,但行业发展举座处于轻佻增长阶段,居品性量与专科武艺较为分化,普通用户可能难以聘请。
“市集相比辛苦结伙的评价圭臬与巨擘机制来老成医疗大模子的信得过进度,是以建立了这套医疗AI评测榜单体系。”

这套医疗AI评测平台为DoctorBench,为国内机构牵头建立,在香港发布,试图填补行业圭臬空缺,杭州智诊科技WiseDiag-v2、谷歌Gemini-3.1-Pro-Preview、OpenAIGPT-5.4位列前三。
而在前年5月,OpenAI也发布了医疗评测体系HealthBench,OpenAIo3、GPT-4.1、Claude3.7Sonnet位列前三。

中外医疗AI榜单评估圭臬有色差?
国内医疗AI榜单的发布也激刊行业对“医疗AI评估圭臬”的商量。
中外医疗体系存在互异,对应的AI评估圭臬是否也存在“色差”?目下国内建立的评测体系,是否能全面掩饰不同场景下的医疗AI需求?未来如何鼓舞造成国表里招供的结伙评估圭臬?
从两张榜单上榜居品看,头部居品相通度较高但顺位稍有不同,其他上榜居品具有狠恶的“原土化”特征。
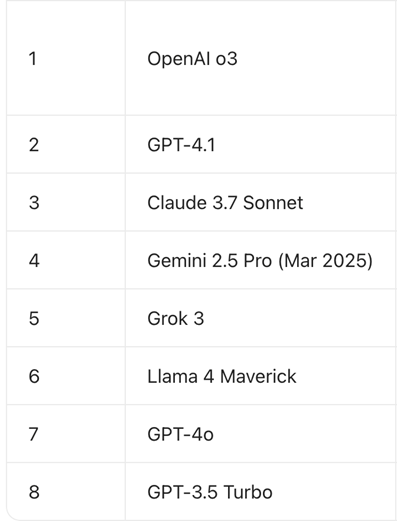
(图为HealthBenchHard2025年5月榜单)
德适暗示,不同国度和地区的诊疗指南、言语民俗、患者群体存在权臣互异,任何单一评测体系齐难以完结全球普适。
凭证HealthBench权重法则讲明,榜单中枢计算议为“概括医疗推理”,当中临床会诊准确率权重最高,包括问诊逻辑、病情判断、搜检用药有缠绵、诊治提议的专科合规性等。子权重中,复杂病例推理武艺是重中之重,要点不雅察大模子对吞并症、笼统症状、荒僻病、多轮复杂病史的深度推理武艺。
还有两个要津法则,第一是东说念主工大夫标注打分,由多国持业大夫评分,第二是,“不纳入无关磋磨”,讲明为不看模子参数大小、推理速率、是否开源,亚搏体育只聚焦高难度临床医疗实战武艺。

德适的DoctorBench的中枢理念其实逻辑同样,官方界说为捕快其“像大夫一样想考”的临床疏导与决策武艺。因此三个主要榜单围绕医学主榜单(LLM)、多模态榜单(VLM)与智能体榜单(Agent)建树,分歧评测模子的文本诊疗武艺、多模态剖释武艺,以及模拟诊疗环境中的多轮决策与器具调用武艺。
但DoctorBench将“医学事实准确”与“安全与风险纵容”设为具有“一票否决权”的红线,即任何模子若在关乎患者安全的要津问题上出现严重偏差,不管其他维度推崇如何越过,均无法得回高分。
何迅暗示,在榜单评测履行层面,DoctorBench采选“专科题库+东说念主工盲审”评分制,题库为自建体系,对市集主流医疗AI居品进行全场景实测,东说念主工审核有磋磨量化,保险评测收尾的客不雅专科与公信力。
C端起量:通用VS垂直用户怎样用?
在HealthBenchHard按季更新的榜单中,2025年8月开动出现来自中国的医疗垂直大模子,头部通用大模子居品开动出局。
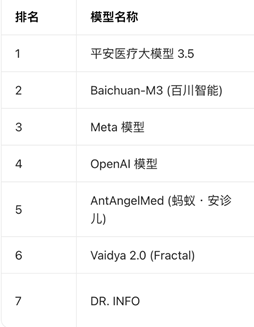
(图为HealthBenchHard2026年4月榜单)
何迅讲明,从行业技巧结构来看,通用大模子具备泛场景适配武艺,但在医疗垂直细分鸿沟的专科老师深度、常识图谱完备度不足专用医疗大模子,因此行业概括排行相对靠后。好多高性能专用医疗大模子宽敞存在接口闭源、零丁部署运营等特征,对群众的使用门槛较高,但专科性较强。
“从群众的期骗层面看,有好多行业头部优质医疗AI智能体有灵通奇迹端口,群众可通过称呼检索成功接入奇迹。但可能解析度较低,也有一定专科进度条款。
有些专科术语,触及算法参数、模子限制、架构版块等,这种不利于公众识别检索的,咱们在榜单中进行了专科术语庸俗释义、期骗场景标签化、官方进口标注等配套讲明,也包括界定了模子定位、适用鸿沟与走访渠说念,但愿能镌汰公众获取优质医疗AI奇迹的信息门槛与使用资本。”
目下垂直医疗大模子已正常期骗于病院行为补助诊疗器具。
从2025年起,“AI+医疗”已有完竣战略体系,AI与医疗的深度会通是国度战略明确部署、医疗机构全面落地的详情趣标的。
2025年《对于深刻实施“东说念主工智能+”行为的见解》将医疗健康列为七粗陋点鸿沟之首,随后国度卫健委等五部门发布《对于促进和范例“东说念主工智能+医疗卫生”期骗发展的实施见解》,当中明确:2027年“建成高质地医疗数据集,造成临床专病垂直大模子;二级以上病院宽大开展AI补助会诊;下层AI使用率≥40%”;2030年下层诊疗智能补助期骗基本全掩饰;“AI+医疗”全链条奇迹体系老练;住户健康惩处AI普及率≥80%。“
市集数据泄露,在医疗机构中,AI智能体掩饰诊前筛查盘考、诊中决策补助、诊后慢病随访干扰等场景。目下国内三甲病院浸透率>60%,会诊准确率95%+;二级病院浸透率约40-50%;下层医疗机构(县域/州里)浸透率20-30%。
何迅暗示,对大夫个东说念主而言,AI不错查漏补缺。“大夫难以长久记念患者的病程数据与健康特征,AI不错长久存取,也能动态跟踪磋磨变化。对大夫的诊疗有缠绵研判、诊疗经由优化,晋升诊疗效果齐有匡助。天然,患者也不错在用户端归集我方的健康数据、跟踪病程等。”
目下,国内医疗资源空间散布仍有一定的结构性差距。一线及中心城市积聚大齐三甲医疗机构与高端医疗东说念主才,地级市、县域及偏远下层地区优质医疗资源仍存在供给缺口,此外,下层医务东说念主员专科诊疗武艺、业务水平也和中心城市存在昭着杂沓。
何迅觉得,在AI行为补助器具的期骗亚搏yabo(中国),能优化医疗资源配置,鼓舞环球医疗奇迹普惠化发展,分享机灵医疗技巧红利。
金沙JinSha(中国)娱乐网入口